Install Kubeflow on IKS
This guide describes how to use the kfctl binary to deploy Kubeflow on IBM Cloud Kubernetes Service (IKS).
Prerequisites
-
Authenticate with IBM Cloud
Log into IBM Cloud using the IBM Cloud Command Line Interface (CLI) as follows:
ibmcloud loginOr, if you have federated credentials, run the following command:
ibmcloud login --sso -
Create and access a Kubernetes cluster on IKS
To deploy Kubeflow on IBM Cloud, you need a cluster running on IKS. If you don’t have a cluster running, follow the Create an IBM Cloud cluster guide.
Run the following command to switch the Kubernetes context and access the cluster:
ibmcloud ks cluster config --cluster <cluster_name>Replace
<cluster_name>with your cluster name.
Storage setup for a classic IBM Cloud Kubernetes cluster
Note: This section is only required when the worker nodes provider WORKER_NODE_PROVIDER is set to classic. For other infrastructures, IBM Cloud Storage with Group ID support is already set up as the cluster’s default storage class.
When you use the classic worker node provider of an IBM Cloud Kubernetes cluster, it uses the regular IBM Cloud File Storage based on NFS as the default storage class. File Storage is designed to run RWX (read-write multiple nodes) workloads with proper security built around it. Therefore, File Storage does not allow fsGroup securityContext unless it’s configured with Group ID, which is needed for the OIDC authentication service and Kubeflow Jupyter server.
Therefore, you’re recommended to set up the default storage class with Group ID support so that you can get the best experience from Kubeflow.
-
Set the File Storage with Group ID support as the default storage class.
NEW_STORAGE_CLASS=ibmc-file-gold-gid OLD_STORAGE_CLASS=$(kubectl get sc -o jsonpath='{.items[?(@.metadata.annotations.storageclass\.kubernetes\.io\/is-default-class=="true")].metadata.name}') kubectl patch storageclass ${NEW_STORAGE_CLASS} -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}' # List all the (default) storage classes kubectl get storageclass | grep "(default)"Example output:
ibmc-file-gold-gid (default) ibm.io/ibmc-file Delete Immediate false 14h -
Make sure
ibmc-file-gold-gidis the only(default)storage class. If there are two or more rows in the above output, unset the previous(default)storage classes with the command below:kubectl patch storageclass ${OLD_STORAGE_CLASS} -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"false"}}}'
Storage setup for vpc-gen2 IBM Cloud Kubernetes cluster
Note: To deploy Kubeflow, you don’t need to change the storage setup for vpc-gen2 Kubernetes cluster.
Currently, there is no option available for setting up RWX (read-write multiple nodes) type of storages.
RWX is not a mandatory requirement to run Kubeflow and most pipelines.
It is required by certain sample jobs/pipelines where multiple pods write results to a common storage.
A job or a pipeline can also write to a common object storage like minio, so the absence of this feature is
not a blocker for working with Kubeflow.
Examples of jobs/pipelines that will not work, are:
Distributed training with tf-operator
If you are on vpc-gen2 and still need RWX, you may try portworx enterprise product.
To set it up on IBM Cloud use the portworx install with IBM Cloud guide.
Installation
Choose either single user or multi-tenant section based on your usage.
If you’re experiencing issues during the installation because of conflicts on your Kubeflow deployment, you can uninstall Kubeflow and install it again.
Single user
Run the following commands to set up and deploy Kubeflow for a single user without any authentication.
Note: By default, Kubeflow deployment on IBM Cloud uses the Kubeflow pipeline with the Tekton backend.
If you want to use the Kubeflow pipeline with the Argo backend, modify and uncomment the argo and kfp-argo applications
inside the kfctl_ibm.yaml below and remove the kfp-tekton, tektoncd-install, and tektoncd-dashboard applications.
# Set KF_NAME to the name of your Kubeflow deployment. This also becomes the
# name of the directory containing your configuration.
# For example, your deployment name can be 'my-kubeflow' or 'kf-test'.
export KF_NAME=<your choice of name for the Kubeflow deployment>
# Set the path to the base directory where you want to store one or more
# Kubeflow deployments. For example, /opt/.
# Then set the Kubeflow application directory for this deployment.
export BASE_DIR=<path to a base directory>
export KF_DIR=${BASE_DIR}/${KF_NAME}
# Set the configuration file to use, such as:
export CONFIG_FILE=kfctl_ibm.yaml
export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/v1.2-branch/kfdef/kfctl_ibm.v1.2.0.yaml"
# Generate Kubeflow:
mkdir -p ${KF_DIR}
cd ${KF_DIR}
curl -L ${CONFIG_URI} > ${CONFIG_FILE}
# Deploy Kubeflow. You can customize the CONFIG_FILE if needed.
kfctl apply -V -f ${CONFIG_FILE}
-
${KF_NAME} - The name of your Kubeflow deployment. If you want a custom deployment name, specify that name here. For example,
my-kubefloworkf-test. The value of KF_NAME must consist of lower case alphanumeric characters or ‘-’, and must start and end with an alphanumeric character. The value of this variable cannot be greater than 25 characters. It must contain just a name, not a directory path. This value also becomes the name of the directory where your Kubeflow configurations are stored, that is, the Kubeflow application directory. -
${KF_DIR} - The full path to your Kubeflow application directory.
The Kubeflow endpoint is exposed with NodePort 31380. If you don’t have any experience on Kubernetes, you can expose the Kubeflow endpoint as a LoadBalancer and access the EXTERNAL_IP.
Multi-user, auth-enabled
Run the following steps to deploy Kubeflow with IBM Cloud AppID as an authentication provider.
The scenario is a Kubeflow cluster admin configures Kubeflow as a web application in AppID and manages user authentication with builtin identity providers (Cloud Directory, SAML, social log-in with Google or Facebook etc.) or custom providers.
-
Set up environment variables:
export KF_NAME=<your choice of name for the Kubeflow deployment> # Set the path to the base directory where you want to store one or more # Kubeflow deployments. For example, use `/opt/`. export BASE_DIR=<path to a base directory> # Then set the Kubeflow application directory for this deployment. export KF_DIR=${BASE_DIR}/${KF_NAME} -
Set up configuration files:
export CONFIG_FILE=kfctl_ibm_multi_user.yaml export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/v1.2-branch/kfdef/kfctl_ibm_multi_user.v1.2.0.yaml" # Generate and deploy Kubeflow: mkdir -p ${KF_DIR} cd ${KF_DIR} curl -L ${CONFIG_URI} > ${CONFIG_FILE}
Note: By default, the IBM configuration is using the Kubeflow pipeline with the Tekton backend.
If you want to use the Kubeflow pipeline with the Argo backend, modify and uncomment the argo and kfp-argo-multi-user applications
inside the kfctl_ibm_multi_user.yaml and remove the kfp-tekton-multi-user, tektoncd-install, and tektoncd-dashboard applications.
-
Deploy Kubeflow:
kfctl apply -V -f ${CONFIG_FILE} -
Wait until the deployment finishes successfully — for example, all pods should be in the
Runningstate when you run the command:kubectl get pod -n kubeflow -
Follow the Creating an App ID service instance on IBM Cloud guide for Kubeflow authentication. You can also learn how to use App ID with different authentication methods.
-
Follow the Registering your app section of the App ID guide to create an application with type regularwebapp under the provisioned AppID instance. Make sure the scope contains email. Then retrieve the following configuration parameters from your AppID:
clientIdsecretoAuthServerUrl
-
Register the Kubeflow OIDC redirect page. The Kubeflow OIDC redirect URL is
http://<kubeflow-FQDN>/login/oidc.<kubeflow-FQDN>is the endpoint for accessing Kubeflow. By default, the<kubeflow-FQDN>on IBM Cloud is<worker_node_external_ip>:31380. If you don’t have any experience on Kubernetes, you can expose the Kubeflow endpoint as a LoadBalancer and use the EXTERNAL_IP for your<kubeflow-FQDN>.
Then, you need to place the Kubeflow OIDC redirect URL under Manage Authentication > Authentication settings > Add web redirect URLs.
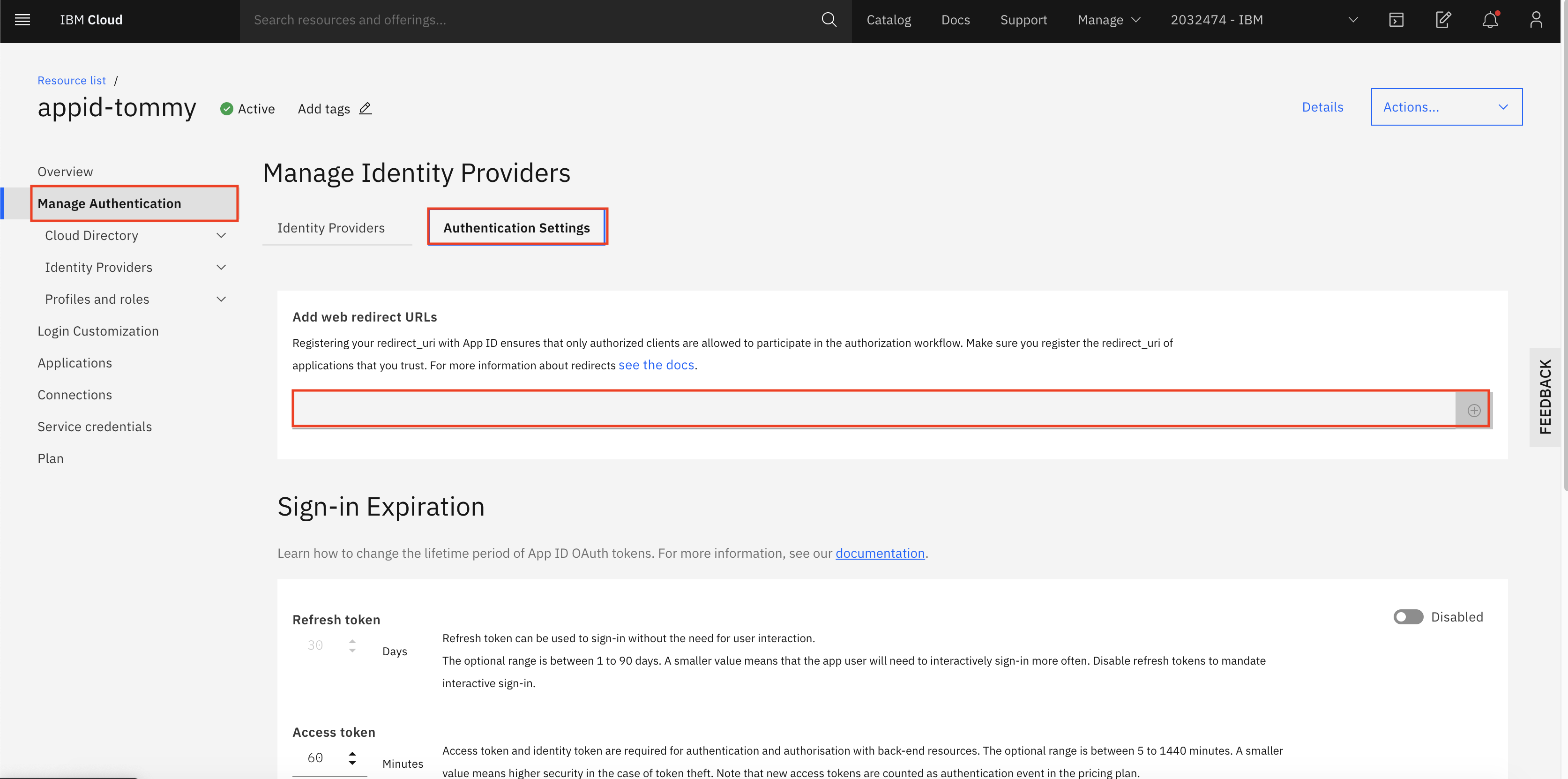
-
Create the namespace
istio-systemif it does not exist:kubectl create namespace istio-system -
Create a secret prior to Kubeflow deployment by filling parameters from the step 2 accordingly:
kubectl create secret generic appid-application-configuration -n istio-system \ --from-literal=clientId=<clientId> \ --from-literal=secret=<secret> \ --from-literal=oAuthServerUrl=<oAuthServerUrl> \ --from-literal=oidcRedirectUrl=http://<kubeflow-FQDN>/login/oidc<oAuthServerUrl>- fill in the value of oAuthServerUrl<clientId>- fill in the value of clientId<secret>- fill in the value of secret<kubeflow-FQDN>- fill in the FQDN of Kubeflow, if you don’t know yet, just give a dummy one likelocalhost. Then change it after you got one.
Note: If any of the parameters are changed after the initial Kubeflow deployment, you will need to manually update these parameters in the secret
appid-application-configuration. Then, restart authservice by running the commandkubectl rollout restart sts authservice -n istio-system.
Verify mutli-user installation
Check the pod authservice-0 is in running state in namespace istio-system:
kubectl get pod authservice-0 -n istio-system
Extra network setup requirement for vpc-gen2 clusters only
Note: These steps are not required for classic clusters, i.e. where WORKER_NODE_PROVIDER is set to classic.
A vpc-gen2 cluster does not assign a public IP address to the Kubernetes master node by default.
It provides access via a Load Balancer, which is configured to allow only a set of ports over public internet.
Access the cluster’s resources in a vpc-gen2 cluster, using one of the following options,
-
Load Balancer method: To configure via a Load Balancer, go to Expose the Kubeflow endpoint as a LoadBalancer. This method is recommended when you have Kubeflow deployed with Multi-user, auth-enabled support — otherwise it will expose cluster resources to the public.
-
Socks proxy method: If you need access to nodes or NodePort in the
vpc-gen2cluster, this can be achieved by starting another instance in the samevpc-gen2cluster and assigning it a public IP (i.e. the floating IP). Next, use SSH to log into the instance or create an SSH socks proxy, such asssh -D9999 root@new-instance-public-ip.
Then, configure the socks proxy at localhost:9999 and access cluster services.
kubectl port-forwardmethod: To access Kubeflow dashboard, runkubectl -n istio-system port-forward service/istio-ingressgateway 7080:http2. Then in a browser, go tohttp://127.0.0.1:7080/
Important notice: Exposing cluster/compute resources publicly without setting up a proper user authentication mechanism
is very insecure and can have very serious consequences(even legal). If there is no need to expose cluster services publicly,
Socks proxy method or kubectl port-forward method are recommended.
Next steps: secure the Kubeflow dashboard with HTTPS
Prerequisites
For both classic and vpc-gen2 cluster providers, make sure you have Multi-user, auth-enabled Kubeflow set up.
Setup
Follow the steps in Exposing the Kubeflow dashboard with DNS and TLS termination. Then, you will have the required DNS name as Kubeflow FQDN to enable the OIDC flow for AppID:
-
Follow the step Adding redirect URIs to fill a URL for AppID to redirect to Kubeflow. The URL should look like
https://<kubeflow-FQDN>/login/oidc. -
Update the secret
appid-application-configurationwith the updated Kubeflow FQDN to replace<kubeflow-FQDN>in below command:
redirect_url=$(printf https://<kubeflow-FQDN>/login/oidc | base64 -w0) \
kubectl patch secret appid-application-configuration -n istio-system \
-p $(printf '{"data":{"oidcRedirectUrl": "%s"}}' $redirect_url)
- Restart the pod
authservice-0:
kubectl rollout restart statefulset authservice -n istio-system
Then, visit https://<kubeflow-FQDN>/. The page should redirect you to AppID for authentication.
Additional information
You can find general information about Kubeflow configuration in the guide to configuring Kubeflow with kfctl and kustomize.
Troubleshooting
Expose the Kubeflow endpoint as a LoadBalancer
By default, the Kubeflow deployment on IBM Cloud only exposes the endpoint as NodePort 31380. If you want to expose the endpoint as a LoadBalancer, run:
kubectl patch svc istio-ingressgateway -n istio-system -p '{"spec": {"type": "LoadBalancer"}}'
Then, you can locate the LoadBalancer in the EXTERNAL_IP column when you run the following command:
kubectl get svc istio-ingressgateway -n istio-system
There is a small delay, usually ~5 mins, for above commands to take effect.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.