Data Management
Out of date
This guide contains outdated information pertaining to Kubeflow 1.0. This guide needs to be updated for Kubeflow 1.1.Since a data scientist can build hundreds of different variants of their models, the ability to quickly create new models and save the code and data of each version is critical for faster iterations and better models. Automating workflows and keeping track of the machine learning (ML) code, packages, libraries, data sets and artifacts for each ML pipeline step requires integrated data management systems and processes.
As a leading contributor to Kubeflow, Arrikto incorporates its standards-based, scale-out storage and data management solution (Rok) with Kubeflow. Arrikto’s Rok presents a Kubernetes storage class to Kubeflow and integrates with the critical Kubeflow components. Rok’s built-in integration simplifies operations, boosts performance, and enables best practices for efficient data versioning, packaging, and secure sharing across teams and cloud boundaries.
The screenshot below shows the Snapshot Store option that Rok adds to the left-hand navigation panel in the Kubeflow UI:
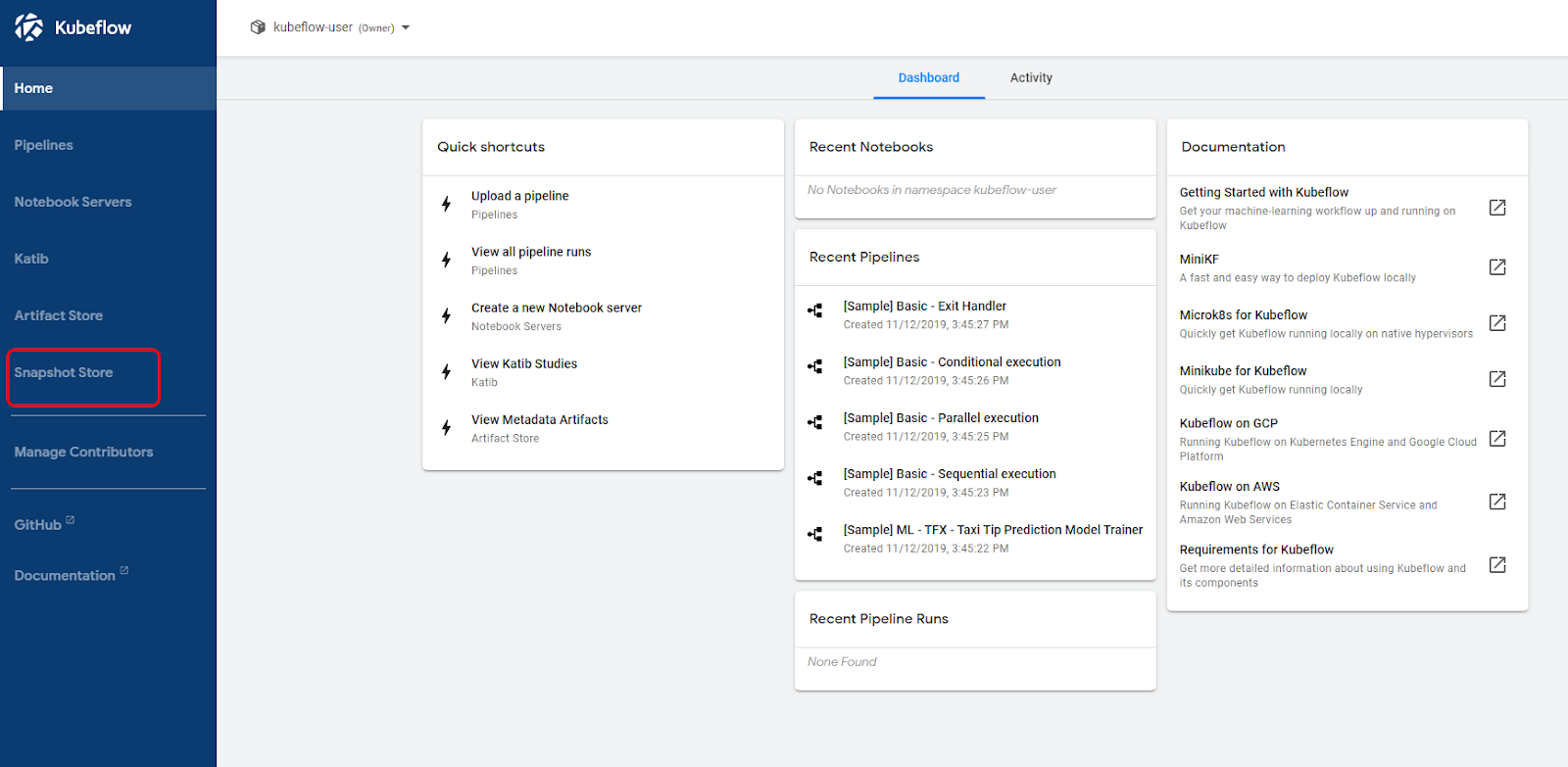
To experience the value of Kubeflow and Rok, follow this hands-on tutorial.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.